オフラインリアルタイムどう書くE01参加しました
はじめに
2016/2/6開催の「オフラインリアルタイムどう書くE01」に参加しましたので、そのレポートです。
組んだプログラム ( の完成版 ) の解説もありますよ。
どんな感じ?
私は初参加だったのですが、今回から ( 今までの横浜でなく ) 秋葉原の永和マネジメントシステムさんに場所をお借りしてやることに。
そちらの社員の方も含めて15名でしたが、場所が快適で良かったですね ( 有難うございます!! )。
…最初の自己紹介でのお題「最近失敗したこと」からすると、永和の方はどうもお酒に呑まれて…。…。…何でしたっけ。思い出せません!!
さて、今回は問題が難しめで1時間で解けたのはしえるさんただ一人 ( 強い!! ) 時間を延長して、テストケースを幾つか通せた人は ( 私を含め ) 出たものの 、死屍累々ということで、鍋谷さん平謝り状態でした。パッと見簡単そうに見えるのですが、キチンと処理するのはなかなか大変だった、という感じでした。
問題
問題は鍋谷さんのサイトにあります。なお、解答例掲載 ( および募集 ) がqiitaの記事にもありますのでどうぞ。
概要としては、
- ある正方形のフィールドが、幾つかの異なる大きさの正方形 ( 1辺の長さは整数 ) で埋め尽くされている
- そのフィールド全体を時計回りに90°回転した時、指定の「グループ」に含まれる正方形のサイズを全て、「早い」順に出力する
- 「グループ」とは、そこに含まれる正方形の上辺が一直線に途切れなく続くものを言う
- 「早い」とは、フィールドの中で上辺の位置が上の方、それが同じなら正方形の位置が左の方を指す
- 入力は1行で、「出力対象のグループ番号 ( 1開始 )」「(回転前の)各グループに含まれる正方形のサイズのリスト(早い順)」が、"G:(s,…,s)(s,…,s)…(s,…,s)" のように、グループ番号はコロン区切り、グループは () でグルーピング、正方形サイズはカンマ区切りとなっている。
…言葉で整理した方が分かりにくいかもしれませんね。
解説
会場の傾向
「同じサイズの正方形がない」ということから、フィールドを格子として管理し、正方形のサイズ別に塗り分けて、そののち回転、そこからグループを探る、という傾向が見られました。
塗り分けまでできている人も大分いて、実際に塗り分けた状態をASCIIアートめいて見られるようにされていて、なかなか壮観でした。
※できたところまでの妥当性が分かるように、テストから先に整備していく、というところにプロを感じますね。
方針
さてしかし。私は塗り分けは最初に捨ててしまいました。なぜかというと、フィールドのサイズが分からなくて面倒だったからです。
…いや、ほんとに。
もちろん、最初のグループを見れば、これが上辺全てを埋める正方形のサイズの集まりなのですから、合計してフィールドのサイズも分かるわけなのですが。まあ、面倒くさがりなんですね。
そこでどう考えたかというと、
- 各グループの正方形の正確な位置が知りたい。
- そのためには、そのグループの高さがどこか。左右の位置がどこになるのかが必要。
- それは、既知のグループの正方形の下辺の情報を整理すれば分かるはず。
- 正方形の位置が分かれば、左辺の位置でグルーピングすることで、回転後のグループが分かるはず。( 90°回転すると、左辺だった辺が上辺になるから )
でした。
ただ、見込みが甘かったのは、
- 上辺の位置が同じ高さであっても、別々のグループになる場合がある ( 途中で別の正方形に邪魔され途切れている…離れ小島パターン )
- 上辺の位置が異なる高さの場合も、下辺がつながって別のグループの天井になるケースがある ( グループの左右のレンジを結合していく必要がある )
- レンジを結合していく場合、必ずしも登場が早い順に位置が整列される訳ではない ( 下辺の位置を見るので )
ちょっとそれでグダってバグが取り切れなかった感じですね…。結果、3割位WA食らいました。
実装
帰宅後、方針はそのままに書き直した実装です。 会場ではRubyの方が大半で、Perlは私1人でしたね…。
なお、全ケース一括で処理できるように、1行ずつ処理するコードになっていますが、別にそうしなければならない訳ではないので念のため。( あくまで1行処理できれば良い )
折角なのでRuby版も。やってることは全く同じです。
詳細
上記コードは、次のような処理をやっています。
- まずグループの解析
- 最初は高さ0、左端0から始まるので、この初期情報をハッシュ hline ( 要素はリスト ) に入れておく
- hline では「下辺の高さ」をキーとして、左右の位置情報 ( 左辺の位置と正方形のサイズ ) を同じ高さの正方形用のリストに追加していく
- 次のグループの選定は「未処理の高さの中で最も高い位置」とする ( そのため処理対象は delete でハッシュから都度消していく )
- 登録されている左右の位置情報は ( 同じ高さの中で ) バラバラなので、sort して処理する
- 直前に処理した正方形の右辺と、今の正方形の左辺が離れた所がグループの切れ目と判断する
- 正方形の位置を解析する毎に、左辺の位置をベースに hline と同じように vline に登録していく
- 次に左辺の位置から指定のグループを探す
- 上でグループを解析した時と同じように、vline を元にグループの切れ目を探していく
- ただし、回転後の状況を考え、sort は降順、直前に処理した正方形の上辺と今の正方形の下辺がつながっているかどうかで見る
- 指定のグループに辿り着いたら ( カウンタ gcount をデクリメントして判断 )、次のグループの切れ目までの正方形がそのままの順番で答えとなる
図解
ケース11 ( 入力: 8:(100,88,76)(27,49)(12,19,39,18)(95,11,6)(3,24)(5,1)(21)(20)(16)(2,47)(77,45)(92)(69,26)(17,60)(43) ) を例に図解してみましょう。
下の図は問題と一緒に用意されていたものです。( 実は問題解くとき見てなかったという… )
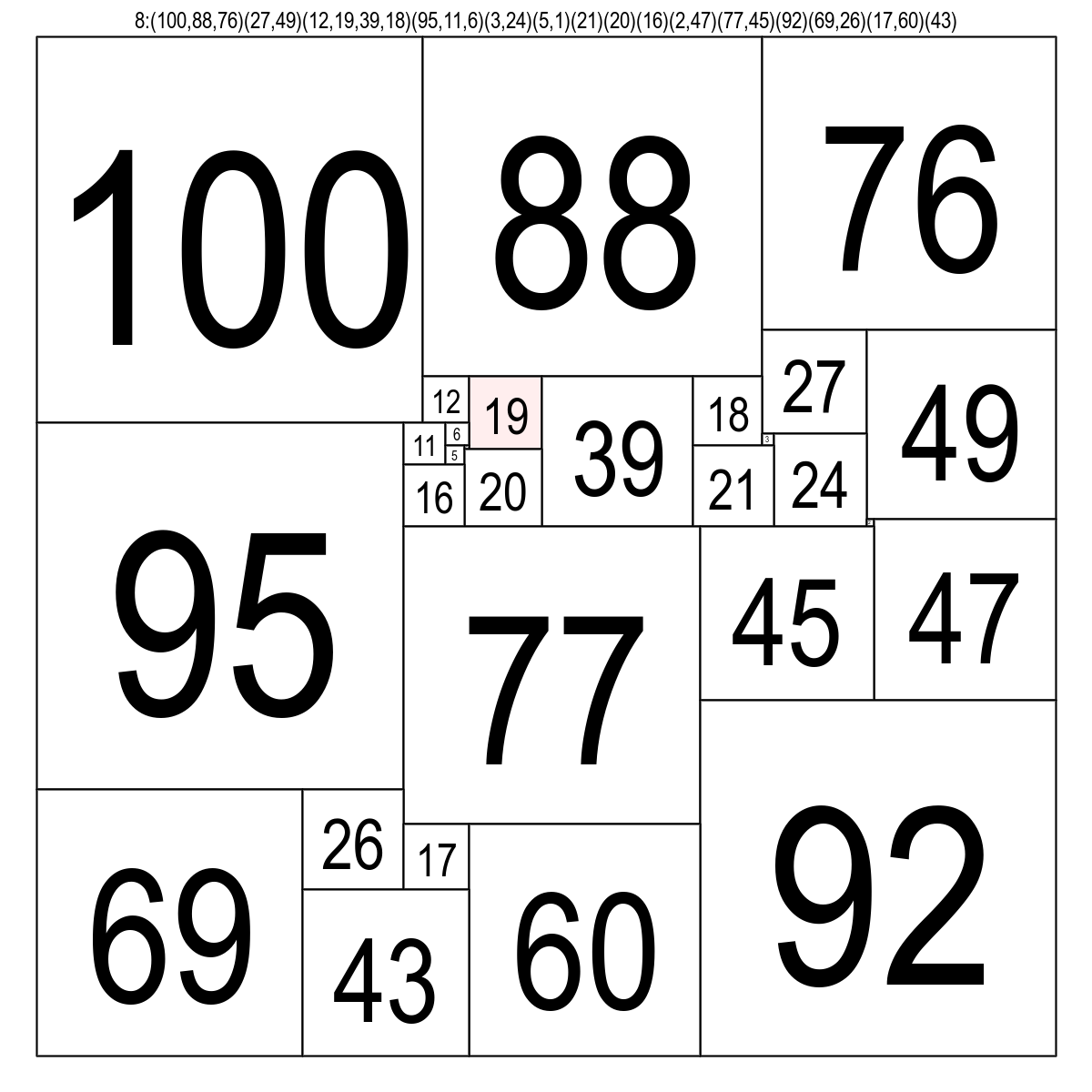
これを「同じ高さ」で塗り分けたのが次の図です。( 同じ色使いまわしてますが、明らかに違う高さの場合はそうだということでお願いします )

大体は同じ色は同じグループということになるのですが、中央の赤いところ、これは同じ高さにありながらグループが異なるという「離れ小島」パターンです。( イヤラシイですね!! )
…さて。同じグループの正方形の情報を入力文字列から処理する際に、下辺の情報を「高さ」別に登録しておきます。これが hline 下の図の実線矢印です。同様に左辺の情報も登録するわけですが、これは vline 点線矢印です。 「高さ」別に分けておけば、少なくとも異なる高さのものは違うグループだと、この時点で篩い分けできるわけです。

さて、では件の「離れ小島」を見てみましょう。グループとしては(5,1)と(21)の所です。先ほどの図から切り取って拡大してます。( 長さの比率なんかはテキトーです )

既にそれまでのグループを処理する中で、hline には図中の矢印に相当する、3種類の情報が登録されています。登録は現れた順にしていましたから、処理する場合は左右の位置でソートしてあげないと役立ちません。で、矢印の始まりと終わりが繋がっているかどうかを見てあげると、赤色の正方形の高さのところは2グループになっている、となるわけです。
なお「未処理の中で一番高い位置」を選び続ければ、そこに今後改めて情報が追加されることはないわけですから、順次グループを処理していけるようになってます。
…図が面倒くさいので描きませんが、vlineから回転後相当のグループ分けをする時も同じ考え方になります。
終わりに
やっぱり時間に追われてやるのは緊張するのか、色々あり得ないミスをしていたのですが…。書き直せばまあ隠蔽されますね。
速攻で、次も来月初めにやろうという話になっていたので、是非また参加したいと思います。今度はその場でのACを目指して!!